April 16, 2025
· 21 min readRAG Chunking Strategies: From Fixed Windows to Content-Aware Intelligence
Choosing the right chunking strategy can make or break your RAG pipeline. In this guide, we explore fixed, semantic, hybrid, and dynamic chunking techniques with Python examples, integration tips for Pinecone, and advice on how to align chunking with your embedding and LLM models.
Retrieval-Augmented Generation (RAG) systems rely on splitting large text data into manageable chunks for embedding and storage in a vector database. Effective chunking is crucial: if chunks are too large, irrelevant content may dilute search results, while too small chunks can miss context. In the original RAG paper, for example, Wikipedia articles were split into disjoint 100-word chunks (yielding ~21 million chunks) to build the retrieval database. This ensures that each chunk is a self-contained unit of information that can be indexed and retrieved independently.
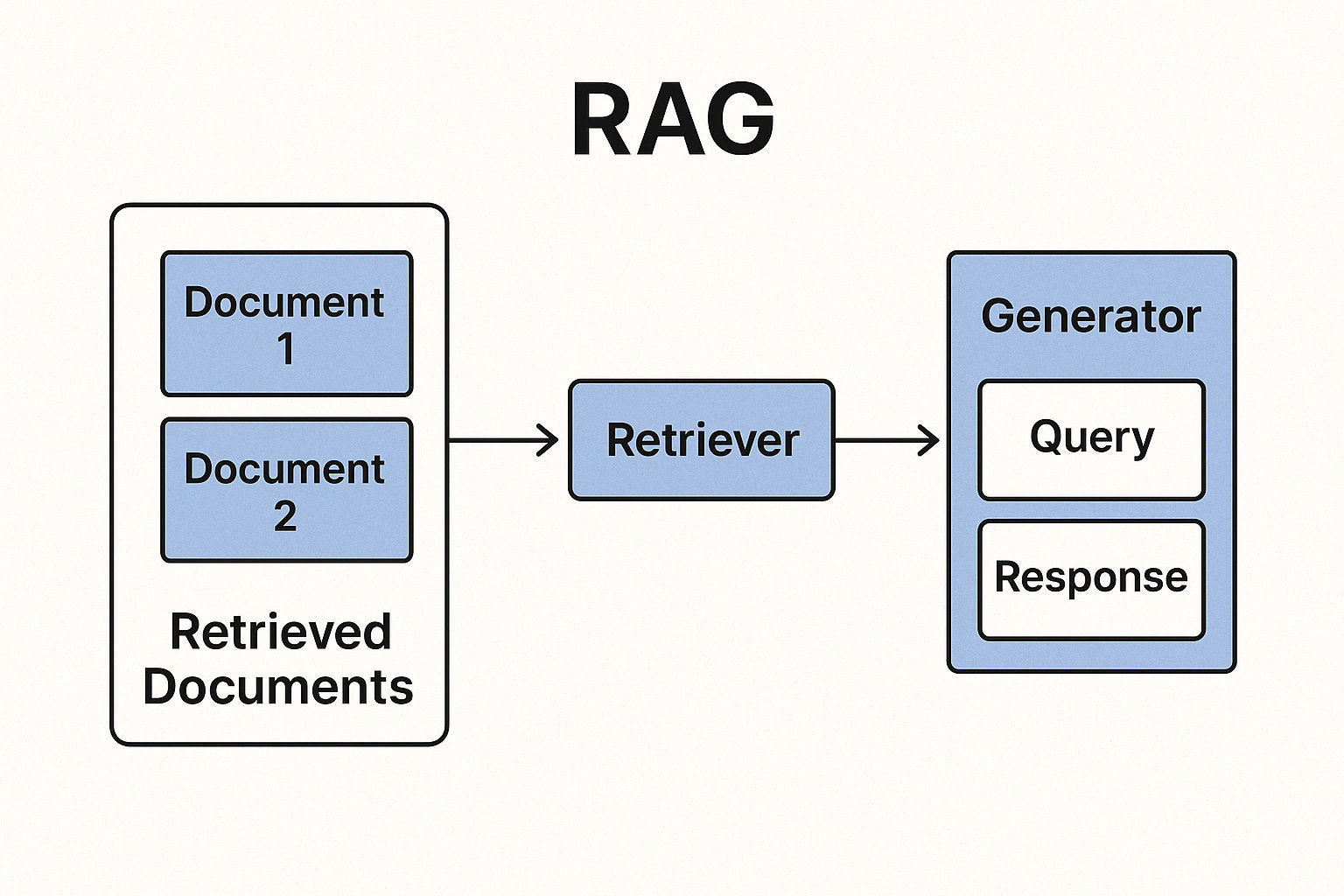
In this guide, we compare common chunking approaches — from simple to advanced — and demonstrate how to implement each in Python. I'll also discuss how to integrate the resulting chunks with a vector store like Pinecone, and how the choice of embedding model (LLaMA-based, multilingual-v5-large, OpenAI, etc.) and its context window influence chunking decisions.
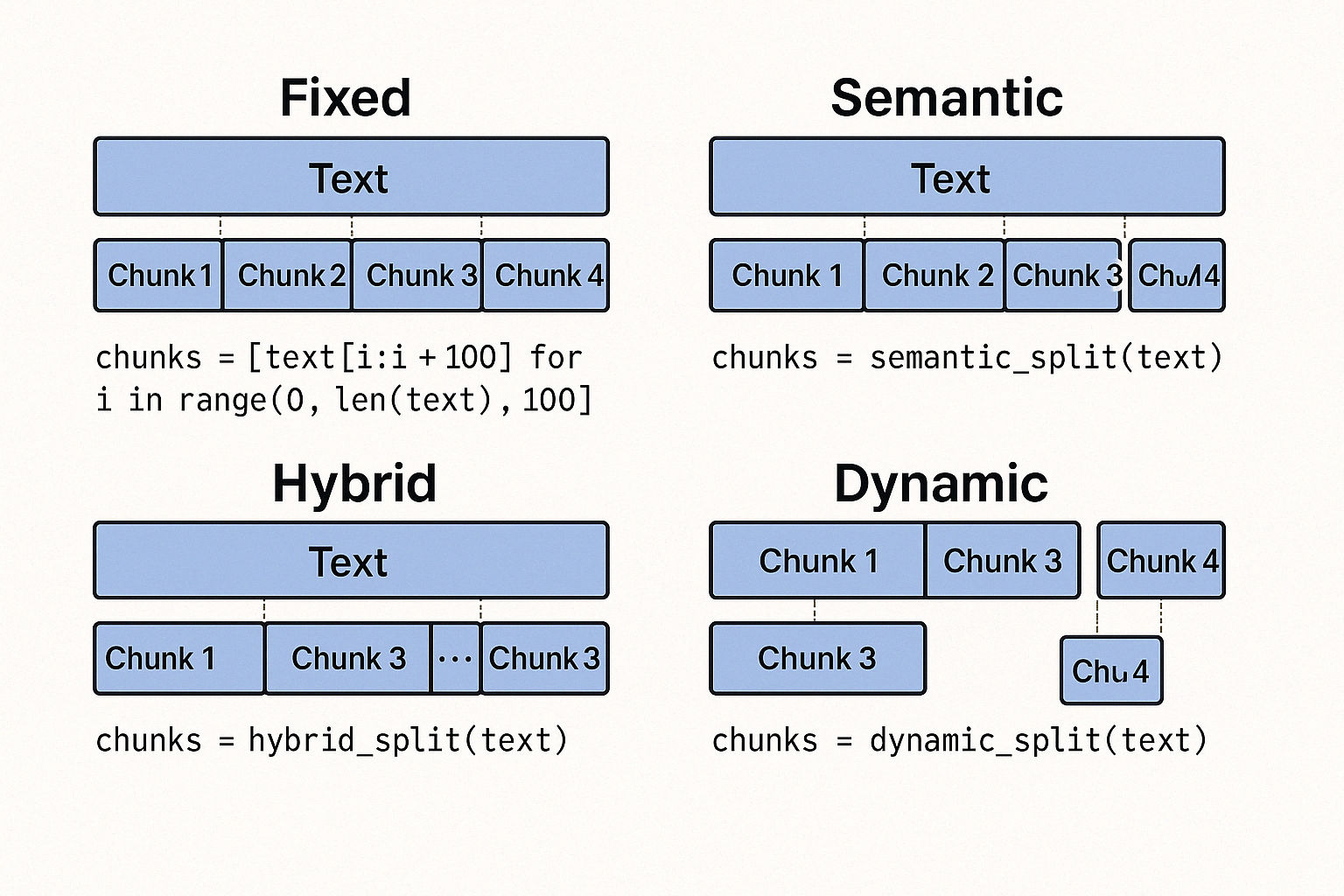
1. Fixed-Length Chunking
How it works:
Fixed-length chunking involves breaking text into equal-sized pieces based on a predefined number of characters, words, or tokens For example, you might split every document into chunks of 100 words or 500 characters regardless of sentence boundaries. This method is straightforward and fast, since it treats the text as a raw sequence without semantic analysis.
Example (Fixed number of words per chunk):
def fixed_length_chunks(text, chunk_size=100):
words = text.split()
# Split the list of words into chunks of length chunk_size
chunks = [' '.join(words[i:i+chunk_size]) for i in range(0, len(words), chunk_size)]
return chunks
# Sample usage
sample_text = "Your long text goes here ... (imagine a few paragraphs of content)."
chunks = fixed_length_chunks(sample_text, chunk_size=50) # 50 words per chunk
print(f"Created {len(chunks)} chunks, first chunk preview:\n{chunks[0][:100]}...")In practice, after chunking, you would embed each chunk and upsert it into a vector store. For example, using Pinecone and a generic embed_fn for embeddings:
import pinecone
pinecone.init(api_key="YOUR_API_KEY", environment="us-west1-gcp") # Initialize Pinecone
# Create or connect to an index (assume an index "documents" exists with appropriate dimensions)
index = pinecone.Index("documents")
# Embed and upsert chunks
for i, chunk in enumerate(chunks):
vector = embed_fn(chunk) # obtain embedding vector for the chunk (using your chosen model)
index.upsert([(f"doc1-chunk-{i}", vector, {"text": chunk})])Integration with Pinecone:
Fixed-length chunks have uniform size, which makes batching and indexing straightforward. Each chunk can be stored with an ID (e.g., combining document ID and chunk number) and metadata (like the original text or source). The uniformity simplifies estimates of index size and query costs, since each chunk yields one embedding of predictable length.
Pros: ✅ Simplicity and speed.
Fixed chunking is easy to implement (as shown above) and computationally efficient. You don't need NLP libraries or complex logic. This approach also ensures consistent embedding sizes and is easy to parallelize. It’s a good default for initial processing or when you need quick indexing of very large corpora.
Cons: ❌ Ignores natural structure.
Fixed-size chunks often split sentences or paragraphs in awkward places, cutting off semantic context Important related information can end up separated, leading to out-of-context retrieval results. Also, this method isn’t flexible — it doesn’t adapt to the content’s structure or meaning. You may retrieve a chunk that is only half of a concept, requiring the generative model to infer missing context (risking errors).
Ideal use cases:
Fixed-length chunking works well when documents are already uniform or when speed is more important than perfect semantic coherence. For example, splitting log files or very large text dumps for a quick analysis, or an initial pass on data to be refined later. It was even used in the original RAG research for scalability (100-word Wikipedia chunks), showing that it can work at scale. However, for nuanced text understanding or QA tasks, more context-aware methods are usually preferable.
2. Semantic Chunking
How it works:
Semantic chunking breaks text into meaningful units, like sentences, paragraphs, or topic sections, rather than arbitrary lengths. The goal is that each chunk contains a complete thought or self-contained piece of information. This often involves using NLP techniques to identify sentence boundaries or section delimiters. For example, you might split on sentence end punctuation or use a library like spaCy or NLTK to split paragraphs and sentences.
Example (Sentence-based chunking with token limit):
import re
def semantic_chunks(text, max_tokens=100):
# Split text into sentences using a simple regex (for demonstration)
sentences = re.split(r'(?<=[.!?]) +', text)
chunks = []
current_chunk = ""
current_length = 0
for sent in sentences:
tokens = sent.split() # tokenizing by whitespace for simplicity
if current_length + len(tokens) <= max_tokens:
current_chunk += (sent + " ")
current_length += len(tokens)
else:
# start a new chunk if adding the next sentence would exceed the token limit
chunks.append(current_chunk.strip())
current_chunk = sent + " "
current_length = len(tokens)
if current_chunk:
chunks.append(current_chunk.strip())
return chunks
# Sample usage
semantic_chunks(sample_text, max_tokens=50) # splits text by sentences, up to 50 tokens per chunkIn this example, we ensure each chunk ends at a sentence boundary (semantic coherence) and also limit the chunk to 50 tokens for consistency. This is a simple hybrid approach to avoid extremely large "semantic" chunks; pure semantic chunking might include whole paragraphs regardless of length.
Integration with Pinecone:
Semantic chunks can be indexed similar to fixed chunks. Each chunk (e.g., a full sentence or paragraph) is embedded and stored with metadata. One consideration is that chunk sizes will vary. Ensure your vector database record can handle the largest expected chunk size (for Pinecone this just affects embedding vector dimension which is fixed by the model, not text length per se). Storing the chunk text as metadata is useful so you can retrieve and highlight the whole sentence/paragraph in responses.
Pros: ✅ Maintains context integrity.
By respecting natural language boundaries, semantic chunking keeps related information together. This improves retrieval relevance, since each chunk is more likely to fully address a part of the query without needing additional pieces. For example, a chunk might correspond to a paragraph about a single topic, which is ideal for answering questions on that topic. This strategy reduces the chance of the model retrieving a fragment that lacks necessary context. In short, the chunks “make sense” on their own, which is a good rule of thumb for chunking.
Cons: ❌ Variable size and complexity.
Implementing semantic chunking is more involved; it requires understanding the text structure via NLP. Chunk lengths will vary, which can complicate batching and memory usage (one chunk might be 20 tokens, another 200 tokens). If chunks are too large (e.g., a very long paragraph), it might hurt retrieval precision or exceed token limits. Also, finding the right boundaries might require language-specific tools (what about punctuation in different languages, or technical text without clear sentences?). Computationally, splitting by sentences or topics can be slightly slower than a simple fixed split, but this overhead is often manageable.
Ideal use cases:
Use semantic chunking for text where preserving meaning is critical. Examples: legal documents, academic papers, or articles where a paragraph or section carries a complete idea. In such cases, chunking by paragraph or section ensures the answer from that chunk is self-contained and accurate. It’s also useful in dialogue or narrative text, where splitting mid-sentence could be very misleading. Whenever you find that fixed chunks return irrelevant results because they cut up ideas, semantic chunking is the remedy.
3. Hybrid Chunking (Semantic + Token-Aware)
How it works:
How it works: Hybrid chunking combines the above approaches to get the best of both worlds. Typically, this means you respect semantic boundaries up to a point, then break if needed to meet a size limit. One common hybrid method is: split text by sentences or paragraphs (semantic), but if a chunk grows beyond a token threshold, split it further. Essentially, it’s semantic chunking with a check on chunk length, ensuring no chunk is too large for the embedding model or context window. Another hybrid approach is a two-pass system – e.g., first do a quick fixed split for indexing, then apply semantic re-splitting when retrieving or as needed. Here we'll focus on the first interpretation (semantic + length limit) since it's more straightforward.
Example (Accumulating sentences up to a token limit):
def hybrid_chunks(text, max_tokens=100):
sentences = re.split(r'(?<=[.!?]) +', text)
chunks = []
current_chunk = ""
current_count = 0
for sent in sentences:
tokens = sent.split()
if current_count + len(tokens) <= max_tokens:
current_chunk += (sent + " ")
current_count += len(tokens)
else:
chunks.append(current_chunk.strip())
current_chunk = sent + " "
current_count = len(tokens)
if current_chunk:
chunks.append(current_chunk.strip())
return chunks
# Sample usage
chunks = hybrid_chunks(sample_text, max_tokens=80)This code is similar to the semantic example but uses a token count (max_tokens) to decide when to start a new chunk. A sentence will start a new chunk if adding it would exceed the limit. The result is that chunks contain whole sentences (no mid-sentence splits), but none exceed ~80 tokens.
Integration with Pinecone:
The integration is the same pipeline: for each chunk, generate an embedding with your model (e.g., multilingual E5-large, OpenAI, etc.) and upsert to the vector DB. One integration tip for hybrid chunking is to store some metadata about the chunk’s position or section. Since hybrid chunks might not align to original paragraphs exactly, storing an identifier like {"doc_id": X, "chunk_index": N} helps you later fetch neighboring chunks or reconstruct context if needed.
Pros: ✅ Balanced approach.
Hybrid chunking preserves context (since it avoids breaking in the middle of a thought) while keeping chunk sizes model-friendly. It strikes a balance between the coherence of semantic chunks and the predictability of fixed-size chunks. You won’t lose important details due to hard cuts, and each chunk will usually fit within token limits for embedding or model context. This often leads to more accurate retrieval than pure fixed-length chunking, without the extreme variability of purely semantic chunks. In essence, you get better recall (chunks are meaningful) and controlled precision (chunks aren’t overly long).
[[NEWSLETTER]]
Cons: ❌ Increased complexity.
Hybrid methods are a bit more complex to implement and tune. You need to choose a token/length limit and still do NLP sentence splitting. Edge cases can arise (e.g., a single sentence longer than the limit—then you must split semantically, perhaps by clauses or just cut it). There is a slight performance cost to doing the extra checks, but it’s usually minor. Another consideration is that hybrid chunking doesn’t inherently account for topic shifts within a long paragraph; it treats every sentence equally. If a document has very dense sections and very sparse sections, a fixed token threshold might still not be optimal for all parts of the document. Thus, hybrid chunking is a general solution, but not specialized to content types or varying writing styles.
Ideal use cases:
This is a great default strategy for varied text data. If you have a mix of documents (blogs, PDFs, webpages) and want one consistent approach, semantic + token-aware chunking is often the safest bet. It’s widely used in many RAG pipelines because it adapts to content structure reasonably well while ensuring chunks fit in the model’s context window. For example, an open-source PDF loader might split by paragraph but cap each chunk at 200 tokens, which works for most use cases. If you suspect fixed-length chunks are too crude but don’t have the capacity for a fully dynamic approach, go hybrid.
4. Dynamic Chunking with Content-Aware Optimization
How it works:
Dynamic chunking is the most advanced approach. Here, the chunking strategy adapts based on the content itself. The idea is to use different rules or even AI feedback to optimize chunk boundaries for each document or section. This can mean leveraging document structure (headings, list items, code blocks, table rows), or using heuristics/ML to find the “best” breakpoints. In practice, dynamic chunking might involve:
- Content-type specific rules: e.g., if the text is recognized as a legal contract, split by sections or clauses; if it's a CSV or table, chunk by row or by a group of rows; if it's code, split by function or logical block. Example: For a news article vs. a contract, you might apply different chunk sizes or splitting logic.
- Complexity or importance-based splitting: Use a model (maybe even the embedding model or an LLM) to detect which parts of the text are dense with information. More complex sections are chunked into smaller pieces, whereas simpler or repetitive sections can be in larger chunks. This could be heuristic (e.g., lots of proper nouns or numbers might indicate dense info) or learned.
- AI-driven chunking: In some cases, an LLM can be prompted to insert markers where splits should occur, ensuring each chunk is a coherent subtopic. This is like asking the model to “outline” or segment the text for you.
Dynamic chunking often requires an initial analysis of the document to choose a strategy. You might even classify documents by type (perhaps using a lightweight classifier or metadata) and then apply different chunking pipelines accordingly.
Example (Content-aware pseudo-code):
def dynamic_chunk(text):
if text.strip().startswith("ID,Name,"): # a simple check for CSV header
return text.splitlines() # each line (row) as a chunk for CSV data
elif "class " in text or "def " in text: # heuristic for code presence
return chunk_code_blocks(text) # assume this splits code into logical blocks
elif len(text) > 10000:
# If very large text, perhaps split by high-level headings first
return split_by_headings(text)
else:
# Default to hybrid splitting for general text
return hybrid_chunks(text, max_tokens=100)
chunks = dynamic_chunk(some_document_text)In this pseudo-code, we choose a chunking method based on simple content cues. A real implementation might use more robust checks or even a classifier to detect document type (e.g., table vs prose vs code). The idea is that different content demands different chunk handling. CSV rows are independent (so keep each row intact), code should not be cut arbitrarily (maybe split by function), and very long texts might be hierarchically chunked (first by section, then subsections).
Integration with Pinecone:
With dynamic chunking, integration is slightly more involved mostly in the metadata. Since chunks come from different strategies, it’s important to store metadata about origin or type. For example, you might tag a chunk with {"doc_type": "csv_row"} or {"section": "Introduction"}. This can help in debugging and even retrieval (you could filter by type if needed). The embedding and upsert step remains the same, but ensure your pipeline is flexible: you might receive 1 chunk from one document and 100 from another, and you might want to assign chunk IDs in a way that encodes the strategy (e.g., "row10" vs "para5"). Pinecone and similar vector stores can handle arbitrary numbers of records, so the main consideration is keeping track of these varied chunks.
Pros: ✅ Maximized relevance through flexibility.
Dynamic chunking can significantly improve retrieval quality for heterogeneous data. By tailoring the chunking to the document, you preserve context and eliminate noise. Each chunk is optimized to be as informative as possible. For instance, splitting a contract by clauses ensures each clause’s obligations stay together, which is far more useful than a blind 200-token window. A content-aware approach is particularly powerful for text-rich, varied sources – when your dataset includes everything from code snippets to tables to long-form text, no single static rule will be optimal. Dynamic chunking addresses that by being adaptive. It also allows finer control over chunk granularity where needed (e.g., important sections get special treatment).
Cons: ❌ High complexity and overhead.
Dynamic chunking is the hardest to implement. It may require developing heuristics for each content type or training models to assist in chunking. This added complexity means more things can go wrong, and maintenance can be difficult as your content types grow. Runtime performance might also be impacted: analyzing a document to decide chunking can be slower than just splitting it. If you use an LLM to find chunk boundaries, that’s an extra API call or model inference per document. In real-time systems, this added latency might be unacceptable. Additionally, with many custom rules, you must ensure consistency — your retrieval system should still treat all chunks uniformly despite them coming from different strategies. Testing and tuning dynamic chunking can be time-consuming, as it’s essentially a custom solution per domain.
Ideal use cases:
Dynamic chunking shines when dealing with very diverse and complex documents, or when you need the absolute best retrieval fidelity. Examples: an enterprise assistant that must handle PDFs (text), Excel files (tables), source code, and web pages. Each of these formats benefits from a different chunking approach, and a dynamic system can route each document to an appropriate strategy. Another use case is when certain parts of documents are much more important than others — e.g., an FAQ section vs. general text — you might chunk the important parts finely and the rest coarsely. If maximum accuracy and context preservation is required (and you have the resources to implement it), dynamic content-aware chunking is the top choice. It’s often used in production RAG systems where data isn’t uniform and mistakes are costly.
Comparison of Chunking Strategies
The table below summarizes the four strategies, comparing how they work, their pros/cons, and when to use each:
| Strategy | How It Works | Pros | Cons | Best For |
|---|---|---|---|---|
| Fixed-Length | Split text into equal chunks of fixed size (e.g. N tokens or words), ignoring content boundaries. | - Fast, simple implementation- Uniform chunk size (easy to index) | - Cuts off context mid-idea - No adaptation to content structure | Initial bulk processing; very uniform or structured text; when speed > context fidelity . |
| Semantic | Split text at natural boundaries (sentence, paragraph, section). Uses NLP to find meaningful breakpoints. | - Preserves complete context in each chunk - Chunks are self-contained (improves relevance) | - Chunk sizes vary (harder to batch) - More complex to implement (needs NLP) | Text that requires context integrity (legal, academic, narratives); situations where coherence outweighs uniformity . |
| Hybrid | Combine semantic splitting with token limits. Accumulate sentences/paragraphs until a size cap, then split. | - Balances coherence and size control - Avoids splitting important info while staying within model limits | - More logic needed (merge two methods)- Still one-size-fits-all for all docs (doesn't account for drastic content differences) | General-purpose chunking for mixed text sources; a safe default when content varies moderately. |
| Dynamic | Adapt chunking to content. Use different strategies per document or section (based on type, importance, etc.), possibly guided by rules or AI. | - Highly flexible per document type - Maximizes relevance by preserving domain-specific context (e.g., tables intact, code blocks intact) | - Most complex to implement and maintain- Higher processing overhead (content analysis step) | Heterogeneous, text-rich data (e.g. pipelines handling articles, code, and tables together); when maximum retrieval accuracy is needed and resources allow. |
Pros/Cons above are relative — a well-tuned system might mitigate some cons. Also, there are variants of these strategies, like overlapping chunks or multi-pass chunking, but we focus on the core idea behind each approach.
Context Window and Embedding Model Considerations
The choice of chunking strategy is closely tied to the embedding model you use and the context window of the downstream LLM that will generate answers. Key considerations include:
-
Embedding model input limits: Different embedding models accept different maximum token lengths. For instance, OpenAI’s
text-embedding-ada-002can handle up to ~8191 tokens per input, whereas many LLaMA-based or BERT-based models have smaller limits (often 512 or 1024 tokens). The multilingual E5-large (v5) model, as an example, truncates inputs beyond 512 tokens. LLaMA 2 models typically allow ~4096 tokens context. This means if you plan to use E5 or a similar model, your chunk size should generally stay under 512 tokens, or you risk losing text (the model will truncate it). With a model like ada-002, you have more leeway to use larger chunks – but bigger isn’t always better (see next point). Always design chunking so that any chunk fits into the embedding model’s input context. -
Optimal chunk size for embeddings: Even if an embedding model allows a large input, very large chunks might dilute the embedding quality. The model has to compress all that information into one vector. Often, moderately sized chunks (a few hundred tokens) yield better embeddings for retrieval than extremely long chunks. In fact, empirical observations have shown that ada-002 often performs well around 256-512 tokens per chunk. Some embedding models (especially sentence-transformer types or older models) are actually tuned to work at sentence or paragraph length – feeding a full chapter into such a model could produce a less useful embedding. Thus, consider the sweet spot for your model: it might be sentence-level for some, or a couple of paragraphs for others. If unsure, err on the side of slightly smaller chunks that are semantically complete.
-
LLM context window (for retrieval and generation): After embedding and retrieving chunks, these chunks (or their text) will be fed into a generative model (like GPT-3.5/4, LLaMA, etc.) as part of the prompt context. This model has its own context window limit (e.g., 4096 tokens for many LLaMA and GPT-3.5 models, up to 8192 or 32000 for GPT-4 variants, etc.). Chunking affects how many retrieved chunks you can supply to the LLM. If your chunks are very large, you might only be able to provide a couple of them before hitting the limit, which means the model sees less diverse information. If chunks are smaller, you can pack more of them in, but each one carries less info. There’s a trade-off between chunk size and number of chunks in context. For example, with a 4096-token LLM context, using four 1000-token chunks might cover four sections of a doc, whereas sixteen 250-token chunks could cover more ground but each with finer detail. Finding the right balance is important. In general, if your retrieval is high-quality, you might prefer slightly larger chunks so that the top 1-3 chunks contain everything needed. But if you want to be safe or cover multiple angles, smaller chunks with a higher
top_kmight be better. Keep in mind that too large chunks risk including unrelated content (which can confuse the LLM or waste space), while too small chunks risk requiring many pieces to answer a single query (which may not all fit in the prompt). -
Hallucination and context handling: If the chunks fed into the LLM are too lengthy, the model might not fully utilize or "pay attention" to all parts, sometimes leading to it ignoring some facts (or worse, hallucinating because it missed them). Conversely, if chunks are too chopped up, the model might miss connections between facts that were split apart. Ensuring each chunk is a coherent piece of knowledge (semantic coherence) helps the LLM use the information properly. One observation is that extremely large retrieved texts can cause the LLM to drift or fill in gaps incorrectly (a form of hallucination). This is why chunking is needed even if you have a 32k context model — feeding it a whole document might not yield the best results, whereas feeding a few focused chunks will.
-
Multilingual and cross-domain considerations: If using a multilingual model like multilingual-v5-large (E5) or others, semantic chunking might need to consider different languages’ sentence boundaries. Some languages don't use periods the same way, or have other indicators of sentences. Similarly, content-aware chunking might need to detect language or format (for example, splitting by punctuation may fail on Chinese text which has different punctuation). Ensure your chunking logic or tools support the kinds of data (language/scripts, formatting) you have. LLaMA-based models fine-tuned on embeddings could be an option for multi-language support, but you would handle them similarly with regard to context length and chunk coherence.
In summary, choose the chunking strategy that best preserves meaningful context within the constraints of your embedding model and LLM. Fixed and semantic chunking are simpler but might falter on highly varied or complex data. Hybrid chunking offers a strong general solution for many cases. Dynamic chunking yields the best results for diverse and large-scale data, at the cost of complexity. Always keep an eye on the model’s context limits – both at embedding time and generation time – as they will guide how large your chunks can be. The ultimate goal is that each chunk is just the right size to make sense on its own and can be effectively matched to queries and inserted into the final answer context. By carefully chunking your text, you enable the RAG system to retrieve and generate with greater accuracy and relevance, unlocking the full potential of your LLM with external knowledge.
References: The strategies and considerations discussed above draw from best practices in recent literature and industry experience. For further reading, you may refer to resources like
Zilliz’s guide on RAG chunking :
Nishad Ahamed’s overview of chunking techniques :
, and others as cited throughout the text. These provide deeper dives and additional context on implementing chunking for RAG. Happy chunking!