August 17, 2025
· 4 min readDemystifying Transformers: A Developer's Guide to Understanding LLMs
Ever wondered how ChatGPT actually generates text that makes sense? This comprehensive guide breaks down transformer architecture, attention mechanisms, and the training process in developer-friendly terms - no PhD required.
The Magic Behind the Curtain
You've probably used ChatGPT, Claude, or another language model and marveled at how it generates coherent, contextual responses. It feels like magic - but it's actually an elegant combination of mathematics, engineering, and massive scale. Let's pull back the curtain and understand exactly how these transformer models work.
Why Transformers Changed Everything
Before transformers, we had sequential models like RNNs and LSTMs that processed text word by word. Imagine trying to understand a sentence by reading it through a narrow window that only shows one word at a time - by the time you reach the end, you've forgotten the beginning.
This created three critical problems:
- Context loss: Important information got lost over long sequences
- Sequential bottleneck: Each word had to wait for the previous one
- Ambiguity resolution: Words with multiple meanings couldn't be disambiguated
Consider: "Sarah bought tickets but they expired." What does "they" refer to? The tickets, not Sarah - but a model that forgets early context might struggle with this reference.
Transformers solved all three through parallel processing and attention mechanisms.
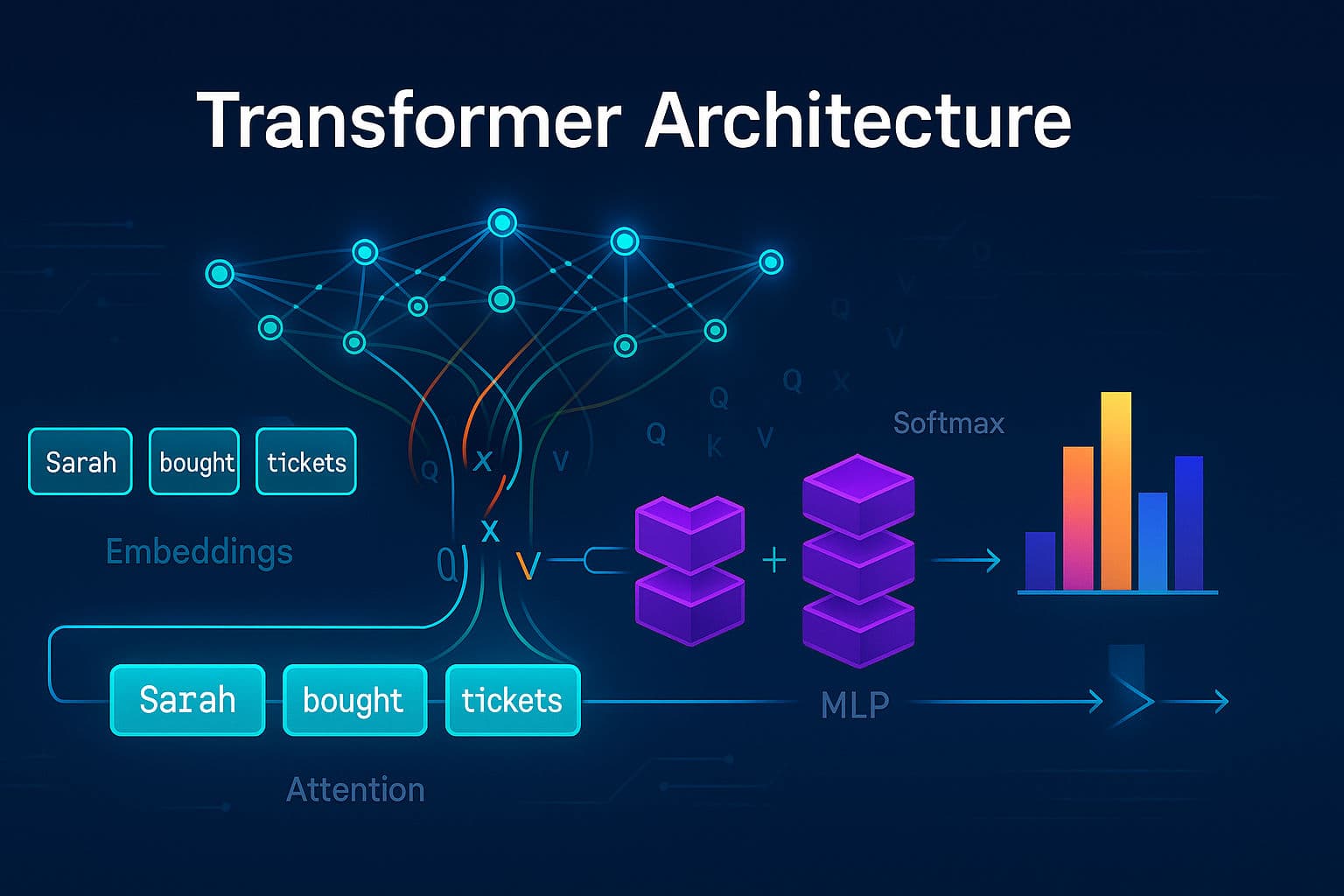
The Architecture: A Highway of Context
Think of a transformer as a highway where information flows from input to output, with multiple stops that add context along the way:
Each stop adds crucial information without losing what came before - it's additive context building.
[[NEWSLETTER]]
Step 1: From Words to Numbers
Tokenization: Breaking It Down
Before a model can process text, it needs to convert words into numbers. Modern models use subword tokenization:
Every word creates queries, keys, and values from the same input embeddings but with different learned weights. The math is surprisingly simple:
MLPs contain ~75% of the model's parameters and act as the "memory bank" where factual knowledge is stored. They take the relationship information from attention and make concrete decisions about meaning.
Training vs Inference: Two Different Modes
Training: Learning from Complete Examples
During training, the model sees complete sentences:
Input: "Sarah bought tickets but they"
Target: "expired"If it predicts "sang" instead of "expired", backpropagation adjusts billions of parameters to make "expired" more likely next time.
Inference: One Token at a Time
During use, it only gets your prompt and generates one token at a time:
Input: "The cat sat on the"
Generate: "mat"
New Input: "The cat sat on the mat"
Generate: "and"
...This autoregressive process continues until the model generates a stop token or reaches a limit.
Modern Innovations
Scale Effects
The transformer architecture scales remarkably well. More parameters, more heads, and more data consistently improve performance:
| Model | Parameters | Heads | Context Length |
|---|---|---|---|
| Original Transformer | 65M | 8 | 512 |
| GPT-3 | 175B | 96 | 4,096 |
| GPT-4 | ~1.7T | Unknown | 32,768+ |
Chain of Thought Reasoning
Modern models can "think step by step" by generating intermediate reasoning before final answers:
Question: What's 127 × 34?
Model thinks: Let me break this down...
127 × 34
= 127 × (30 + 4)
= 127 × 30 + 127 × 4
= 3,810 + 508
= 4,318Mixture of Experts (MoE)
Instead of activating all parameters, route inputs to specialized "expert" networks:
- Math expert for calculations
- Code expert for programming
- Language expert for translation
This allows models with 800B total parameters to only use 20B per forward pass.
Putting It All Together
A transformer is essentially a contextual machine that:
- Converts text to numerical representations
- Adds positional information
- Uses attention to let words communicate
- Employs MLPs to process and store knowledge
- Repeats this process through many layers
- Outputs probability distributions over possible next tokens
The entire process is matrix multiplication and addition - no complex math required. The complexity comes from scale and the emergent behaviors that arise from billions of parameters trained on massive datasets.
Key Takeaways
- Transformers process all words in parallel using attention mechanisms
- Attention is like social networking - words ask questions and share information
- MLPs are the knowledge storage - they contain most of the model's learned facts
- Training shows complete examples while inference generates one token at a time
- Scale effects are real - bigger models consistently perform better
- The math is surprisingly simple - mostly matrix operations that any developer can implement
Understanding transformers demystifies AI and reveals the elegant engineering behind what seems like magic. These models aren't conscious or truly "intelligent" - they're sophisticated pattern matching systems that have learned incredibly rich representations of language and knowledge through massive scale and clever architecture.
References
- Attention Is All You Need - The original transformer paper
- The Illustrated Transformer - Visual explanations
- 3Blue1Brown Neural Networks - Mathematical foundations
- Hugging Face Transformers - Implementation library
- TikToken - Tokenization visualization tool
- Papers With Code - Latest research