Loading…
Tag
#RAG
3 posts

May 31, 2026
PageIndex: The Vectorless RAG That Reasons Through Documents Instead of Embedding Them
Traditional RAG chops documents into arbitrary chunks, embeds them, and hopes cosine similarity finds the right one. PageIndex throws that out — it builds a hierarchical table-of-contents tree and lets an LLM reason its way to the right section, the way a human expert flips to the right chapter. No embeddings, no vector DB. It hit 98.7% on the FinanceBench benchmark.
RAGLLMRetrieval
November 5, 2025
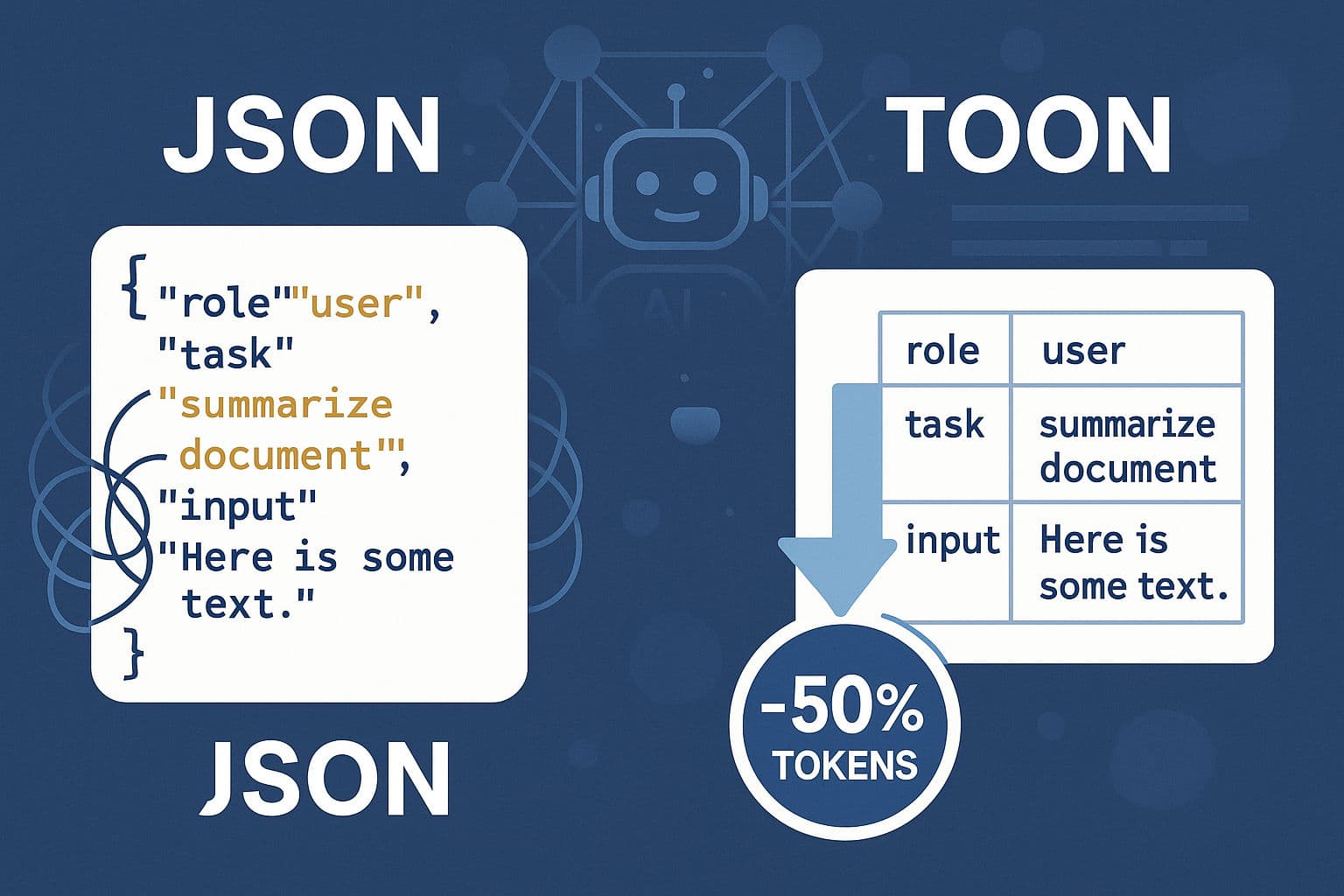
TOON vs JSON: Supercharge Your LLM Prompts & Cut Token Costs
Token-Oriented Object Notation (TOON) is a compact, LLM-optimized alternative to JSON for serializing structured, mostly flat/tabular data. By removing repeated field names, quotes and redundant punctuation, TOON reduces token usage by roughly 30–60% in real-world AI workflows, leading to lower API bills, larger usable context windows, and often better model retrieval accuracy.
AILLMJSON
May 3, 2025
Unlocking Smarter AI: A Deep Dive into Contextual Retrieval for RAG
Retrieval Augmented Generation (RAG) is a powerful technique for building AI applications that answer questions based on specific knowledge sources. While typical RAG involves indexing data (loading, splitting, storing) and then retrieving and generating responses, traditional methods can **destroy context** when documents are split into chunks. This makes retrieval less accurate. **Contextual Retrieval** addresses this by prepending chunk-specific explanatory context, dramatically improving accuracy. This method, including Contextual Embeddings and Contextual BM25, can reduce the top-20-chunk retrieval failure rate by **49%**. Combining Contextual Retrieval with **Reranking** can further reduce the failure rate by up to **67%**. Other techniques like BM25 can also enhance retrieval by leveraging lexical matching. Implementing Contextual Retrieval involves steps like document loading, splitting, LLM-based contextualization (potentially using prompt caching for cost efficiency), embedding, and storing in a vector store. Tools like LangChain and LangGraph can be used for building these RAG applications. Model selection and effective prompting techniques (like GRWC, ERA, APEX) are also crucial for achieving exceptional AI outputs.
AIRAG