May 3, 2025
· 6 min readUnlocking Smarter AI: A Deep Dive into Contextual Retrieval for RAG
Retrieval Augmented Generation (RAG) is a powerful technique for building AI applications that answer questions based on specific knowledge sources. While typical RAG involves indexing data (loading, splitting, storing) and then retrieving and generating responses, traditional methods can **destroy context** when documents are split into chunks. This makes retrieval less accurate. **Contextual Retrieval** addresses this by prepending chunk-specific explanatory context, dramatically improving accuracy. This method, including Contextual Embeddings and Contextual BM25, can reduce the top-20-chunk retrieval failure rate by **49%**. Combining Contextual Retrieval with **Reranking** can further reduce the failure rate by up to **67%**. Other techniques like BM25 can also enhance retrieval by leveraging lexical matching. Implementing Contextual Retrieval involves steps like document loading, splitting, LLM-based contextualization (potentially using prompt caching for cost efficiency), embedding, and storing in a vector store. Tools like LangChain and LangGraph can be used for building these RAG applications. Model selection and effective prompting techniques (like GRWC, ERA, APEX) are also crucial for achieving exceptional AI outputs.
Introduction
Artificial intelligence is rapidly transforming how we work and interact with technology. As Large Language Models (LLMs) become increasingly sophisticated, their potential applications expand dramatically. One of the most powerful areas is building sophisticated question-answering (Q&A) chatbots that can answer questions about specific source information. To achieve this, developers often use a technique called Retrieval Augmented Generation (RAG).
What is RAG?
At its core, RAG is a method that enhances an AI model's knowledge by retrieving relevant information from a knowledge base and incorporating it into the prompt. This is particularly useful when the required information is outside the model's initial training data or needs to be specific to a particular context, such as a company's internal documents or a vast array of legal cases.
A typical RAG application involves two main components that usually happen offline and at runtime:
- Indexing: This pipeline involves ingesting data from a source and preparing it for efficient searching.
- Retrieval and Generation: This is the runtime process where a user query triggers the retrieval of relevant data from the index, which is then used by the language model to generate an answer.
Let's break down the steps involved in each component.
The RAG Pipeline: From Data to Answer
The most common sequence for a RAG application starts with preparing your data:
Indexing:
- Load: Data from a source is loaded using Document Loaders, which return Document objects. For example, a
WebBaseLoadercan load content from web URLs. - Split: Large documents are broken down into smaller chunks using Text Splitters. This is crucial because large chunks are difficult to search effectively and may not fit within an LLM's finite context window. A common method is the
RecursiveCharacterTextSplitter, which splits text based on common separators until chunks are of an appropriate size. - Store: The resulting text chunks need to be stored and indexed so they can be searched later. This is often done using a VectorStore and an Embeddings model. The embedding model converts the chunk content into vector embeddings, and the vector store stores these embeddings, allowing for search based on semantic similarity.
Retrieval and Generation:
- Retrieve: When a user provides an input query, the system uses a Retriever (often leveraging the VectorStore) to find the relevant document splits from storage.
- Generate: The retrieved data, along with the user's original question, is then passed to a ChatModel or LLM, which uses this context to produce an answer.
The Context Challenge in Traditional RAG
While effective, traditional RAG systems face a significant limitation: they can inadvertently destroy context. When documents are split into small chunks for efficient retrieval, individual chunks might lack sufficient surrounding context, making it hard for the system to retrieve the correct information or for the model to use the retrieved information effectively.
Imagine a chunk saying, "The company's revenue grew by 3% over the previous quarter.". Without the surrounding document context, this chunk doesn't specify which company or which quarter, rendering it less useful.
Introducing Contextual Retrieval
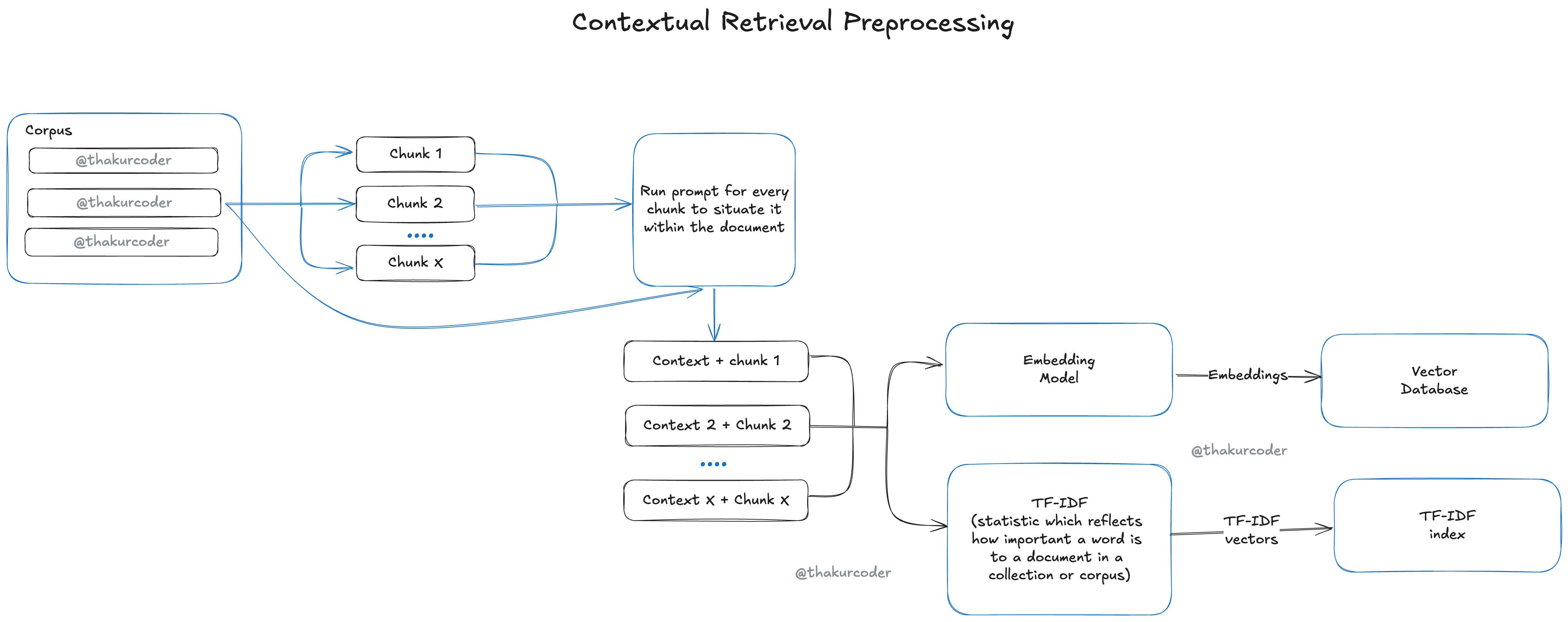
To combat this "context conundrum," a technique called Contextual Retrieval has been introduced. This method aims to dramatically improve the retrieval step in RAG by ensuring that individual chunks retain crucial contextual information.
[[NEWSLETTER]]
Contextual Retrieval works by prepending chunk-specific explanatory context to each chunk before it is embedded or indexed using techniques like BM25. This "contextualized chunk" includes both the original content and a brief explanation situating it within the larger document.
For example, the chunk "The company's revenue grew by 3% over the previous quarter." could be transformed into: "This chunk is from an SEC filing on ACME corp's performance in Q2 2023; the previous quarter's revenue was $314 million. The company's revenue grew by 3% over the previous quarter.".
This contextual information is generated automatically for each chunk by using an LLM, often with a prompt that includes both the whole document and the specific chunk, asking the model to provide a concise context.
The Impact of Contextual Retrieval
Adding this extra layer of context significantly enhances retrieval accuracy. Experiments have shown that Contextual Embeddings alone can reduce the top-20-chunk retrieval failure rate by 35%. When combined with Contextual BM25 (applying the same contextualization to the BM25 indexing process), the retrieval failure rate is reduced by 49%.
This improved retrieval accuracy directly leads to better performance in downstream tasks, as the model is provided with more relevant and understandable information.
Further Enhancements: BM25 and Reranking
Beyond Contextual Retrieval, other techniques can further boost RAG performance.
- BM25 (Best Matching 25) is a ranking function that uses lexical matching to find precise word or phrase matches, building upon TF-IDF. It's particularly effective for queries containing unique identifiers or technical terms that semantic embeddings might miss. Combining embedding search with BM25 can provide a more comprehensive result.
- Reranking is a filtering technique applied after the initial retrieval step. It takes a list of potentially relevant chunks and re-scores them based on their relevance to the query, selecting only the most relevant ones to pass to the generative model. Combining Contextual Retrieval with Reranking has been shown to reduce the top-20-chunk retrieval failure rate by an impressive 67%.
These techniques can be stacked to maximise performance improvements.
Cost and Implementation Considerations
Generating contextual information for thousands or millions of chunks requires processing each chunk with an LLM, which can be costly. However, techniques like prompt caching can significantly reduce costs by allowing models to cache frequently used parts of a prompt (like the full document). Using smaller, cheaper LLMs for the contextualization step also helps manage costs.
When implementing Contextual Retrieval, consider factors like chunk size, chunk boundaries, the choice of embedding model (some benefit more than others), customising the contextualizer prompt for your domain, and the number of chunks passed to the model.
The Role of AI Models and Prompting
The choice of AI model significantly impacts the results of any AI application, including RAG. Different models excel at different tasks:
- Some are best for general conversational exchanges (e.g., GPT-4.5).
- Others specialise in logical reasoning (e.g., DeepSeek).
- Some are optimised for STEM tasks (e.g., OpenAI o3-mini).
- Specific models may focus on code generation, math, or multimodal support (e.g., Mistral Large, Llama 3.1, Gemini).
- Powerful models like Claude 3.7 Sonnet are noted for reflective thinking and handling long documents.
- Even smaller models can be highly effective for specific, less complex tasks like generating contextual information for RAG chunks.
Beyond model selection, the way you phrase your request to the AI (prompting) is critical. Structured frameworks like GRWC (Goal, Return Format, Warnings, Context Dump), ERA (Expectation, Role, Action), and APEX (Action, Purpose, Expectation) can help transform mediocre outputs into exceptional ones by clearly defining objectives, desired formats, constraints, and background information. Advanced techniques like iterative refinement, tone specification, and chain-of-thought prompting can further improve results.
Conclusion
Building accurate and reliable AI applications that leverage external knowledge requires more than just basic RAG. Techniques like Contextual Retrieval are essential for ensuring that the information retrieved is not only relevant but also retains the necessary context for the LLM to generate high-quality, specific answers. By combining Contextual Retrieval with strategies like BM25 and Reranking, and paying careful attention to model selection and sophisticated prompting techniques, developers can build AI systems that effectively access and utilise vast knowledge bases to provide truly insightful responses.
Reference Links: